skip to main |
skip to sidebar
I was recently pointed to Amrit Williams' excellent observations about virtualization -- including the myths and misconceptions about it as well. Amrit's observations are a really great place to start when you're considering a virtualization initiative. Forewarned is forearmed.
A consistent observation we at Cassatt have been professing for some time is that virtualization is not an end-in-itself. It is an enabler of much higher-level data center management structures. So, when virtualization is implemented as if it is the goal, the outcome could easily be more cost and complexity, rather than the reverse. As illustrated by Amrit:
Virtualization reduces complexity (I know what server I am. I’m the server, playing a server, disguised as another server)
It seems counter-intuitive that virtualization would introduce management complexity, but the reality is that all the security and systems management requirements currently facing enterprises today do not disappear simply because an OS is a guest within a virtual environment, in fact they increase. Not only does one need to continue to maintain the integrity of the guest OS (configuration, patch, security, application and user management and provisioning), one also needs to maintain the integrity of the virtual layer as well. Problem is this is done through disparate tools managed by FTE’s (full time employees) with disparate skills sets. Organizations also move from a fairly static environment in the physical world, where it takes time to provision a system and deploy the OS and associated applications, to a very dynamic environment in the virtual world where managing guest systems - VMsprawl - becomes an exercise in whack-a-mole.
 There are also a variety of other perspectives on this new tool called virtualization. Take for example the implicit assumption that *everything* will be virtualized. The answer is maybe, but perhaps not in our lifetime. Begging the question "how to I manage all the other stuff?" The de-facto answer has been that IT uses its existing systems for Physical, and VM management tools for the rest. Now you've bifurcated your datacenter management, and added to complexity once agai n. (Thanks to Amrit for the pic.)
There are also a variety of other perspectives on this new tool called virtualization. Take for example the implicit assumption that *everything* will be virtualized. The answer is maybe, but perhaps not in our lifetime. Begging the question "how to I manage all the other stuff?" The de-facto answer has been that IT uses its existing systems for Physical, and VM management tools for the rest. Now you've bifurcated your datacenter management, and added to complexity once agai n. (Thanks to Amrit for the pic.)
My advice is - and has been - to treat virtualization as a *feature* of something larger. Don't implement it if you're treating it as a point-solution; Treat it as an enabler of your next systems management architecture. Rules-of-thumb have to be
- Assume heterogeneity of VMs & VM management; plan for it
- Assume you'll always have physical servers somewhere; manage them alongside your virtual servers
- Assume you'll have more virtual object to manage than you can keep track of; use an automation tool
- Never assume that once you've consolidated, things will be stable; plan for constant re-adjustment of scale and capacity (another argument for automation)
Have an end-game in sight if your'e introducing VMs in your environment. Take the long-view.
I was pointed to John Foley's InformationWeek article earlier this week of "20 Cloud Computing Startups You Should Know." Aside from the fact I could only count 19, it was a great survey of what types of companies, ideas and ventures are getting on the bandwagon.
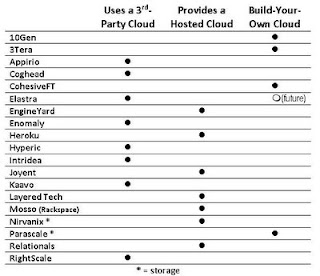 The quick-and-dirty chart above is mine; what I found so interesting is that 8 of the players are building solutions on top of other clouds (like Amazon's EC2 and S3) while another 7 are investing in essentially building hosted services.
The quick-and-dirty chart above is mine; what I found so interesting is that 8 of the players are building solutions on top of other clouds (like Amazon's EC2 and S3) while another 7 are investing in essentially building hosted services.
However, only 4 (ok, maybe 4-1/2) are thinking/trying to bring "cloud" technologies and economics to the enterprise's own internal IT. This certainly attests to the difficulty in reworking IT's entrenched technologies, and building a newer abstracted model of how IT should operate.
Even though Cassatt wasn't mentioned in the survey (maybe we were supposed to be #20) we also play in the "build-an-internal-cloud-with-what-you-have" space.
This model -- that of an "internal cloud" architecture -- will ultimately result in more efficient data centers (these architectures are highly efficient) and ones that will be able to "reach out" for additional resources (if-and-when needed) in an easier manner than today's IT.
I'd look to see more existing enterprises considering building their own cloud architectures (after all, they've already invested lots of $$ in infrastructure) while startups and smaller shops opt for the products that leverage existing (external) cloud resources.
BTW, John also just posted a very nice blog of a "reality check" to curb some of the cloud computing hype.
Right across the street from VMworld was Tier 1's Hosting Transformation Summit. Roughly 400 folks -- mostly from Managed Service Providers (MSPs) -- attended to get the lowdown on where that industry is going. It's changing fast, given some of the recent "cloudy" offerings from Amazon, Mosso, OpSource and others. And part of the driver was the technology offered from VMware itself.
But First: The industry, and its growth, is compelling. Managed services hosting is growing in the U.S. at about 30%/y, and it will be a $10 billion industry by the end of 2008. While about 20% of that amount is represented by 13 of the largest firms, the remainder of the market is represented by hundreds if not thousands of smaller entities.
Dan Golding of Tier 1 pointed out that the categories called "web hosting" and "managed hosting" are colliding, given that so many apps are being delivered over http. He also pointed out that small/medium businesses are expectted to outsource even more of their own IT, as operating it themselves becomes more complex and expensive... also good for MSPs. In particular he noted that CRM, HR, Accounting, fileservers, utility storage, email and project management were expected to be the top managed SaaS applications.
Next, John Zanni, Microsoft's GM of worldwide hosting, gave a talk called "cloud computing - is virtualization enough?" Having seen Paul Maritz' VMworld keynote hours before, I couldn' t help but compare the two. Zanni's a really smart guy -- but vision-wise, his talk was a let-down. While he absolutely identified the same requirements of the "cloud" (which were surprisingly in-agreement with VMware's) Microsoft's vision was elementary in comparison to VMware, referencing Microsoft party-lines and products - and was weak on vision. Granted, the audience was not as heavily-laden with technologists as the VMware conference, but the vision that was sketched-out just didn't seem too fully-baked. One interesting side-note: John explicitly mentioned Microsoft management tools that would someday manage 3rd-party VMs such as VMware. Hmmm....
On day 2, Antonio Piraino (also of Tier 1) gave a really great talk on "virtualization and cloud computing" -- the guy really gets it, with respect to the MSP industry. His message to MSPs was pretty clear: Cloud is coming, and you (the MSP) will need to learn about it and get on board. The definition of "cloud" he gave to MSPs was
- Server-based managed hosting
- Virtualized offerings
- Multi-O/S & DB support
- Automated scalablity
- Easy ordering of services
- On-demand provisioning
- Cross-service integration
- Bill-for-use
- SLAs were managed / managed-for
It's clear that the smaller MSPs out there will be jumping on the Utility Computing, Cloud, PaaS and SaaS bandwagon soon. That should begin to give folks like Mosso, Flexiscale, IronScale, OpSource etc. some competition. But i'm sure we're going to see the concept of abstracted-away hardware grow in popularity with frightening velocity.
I'm a bit late in reporting-back on day #1 of VMworld in Las Vegas. Word-on-the-floor is that there are over 14,000 attendees here. Definitely indicative of the hunger the industry has for this technology.
Rather than re-hash all of what CEO Paul Maritz had to say, I'd like to point out why VMware's vision is both on-the-mark -and- already available from sources other than VMware.... and showcase one such available product
Paul outlined 3 areas of vision:- Virtual Data Center O/S (VDC-OS)
- vCloud (providing the ability to build internal/external clouds and federation between clouds)
- vClient (providing end-client independence for services emanating from clouds
He emphasized, with a demo, how an "internal cloud" could reach-out to an off-premises (external) cloud for resources, say during peaking demand -- or perhaps as a failover scenario. The demo has 3 points to make: (a) the ability to provide "elastic" capacity, (b) the ability to provide self-healing in the form of replacing failed capacity, and (c) the fact that it was driven by policies based on SLAs. It was a demo of a non-commercially-available product, but it drew great applause from the audience.
Whenever the "big guys" show-off a concept/roadmap, you can be sure that there are already smaller guys who are paving the way for them; this is no different. Cassatt, for one, has been showing-off this type of demo (down to a similar GUI) for many months now. With a few key differences:
- The product is shipping today
- We don't require that there are "warm" hosts pre-provisioned as standby resources
- We don't require that VMware is everytwere; in fact, we can already show the same demo but using Xen/Citrix (and soon, with other VM players)
- We don't even require that Virtualization is used at all; our approach works with physical HW and O/Ss too (including x86, SPARC, Linux distros, Solaris, and others)
 For those attending the keynote, perhaps the GUI above looks familiar; except it's Cassatt's Active Response 5.1
For those attending the keynote, perhaps the GUI above looks familiar; except it's Cassatt's Active Response 5.1
In the center is a chart indicating upper- and lower- SLA thresholds (SLAs can be arbitrarily defined and composed). If the upper SLA is breached, Active Response finds bare-metal resources in the "free pool" (again, defined how you like) and then automatically provisions those resources with whatever SW policy determined (read: either a physical server or a virtual server). The application "tier" grows automatically. If/when the lower threshold is breached, an instance on the "tier" is retired. This approach provides real-life SLA management, capacity-on-demand (elastic behavior), failover/availability, and many other nice-to-have properties -- automatically. And Today.
This set of properties were also discussed across the street today at Tier-1 Research Hosting Summit at the Mirage. Many MSPs in the audience wanted to know "how do I get some of that?" when discussion came to utility computing and cloud infrastructures. I'll post on that next :)
It's the first day of VMworld, and already the P/R for new technology and "roadmaps" is flying.
The news that caught my eye was VMware's vCloud & Virtual Data Center O/S (VDC-OS) Initiatives... Strategically, it's a great move for them. They've essentially said "hey, enterprises use VMware internally, and service providers use VMware too. So why not link the two?" Cool idea. Just missing the mark by a teeny bit. An excerpt from their P/R:
Today at VMworld 2008, VMware, Inc. (NYSE: VMW), the global leader in virtualization solutions from the desktop to the datacenter, announced a comprehensive roadmap of groundbreaking new products and technologies that expand its flagship suite of virtual infrastructure into a Virtual Datacenter Operating System (VDC-OS). The Virtual Datacenter OS allows businesses to efficiently pool all types of hardware resources - servers, storage and network – into an aggregated on-premise cloud – and, when needed, safely federate workloads to external clouds for additional compute capacity. Datacenters running on the Virtual Datacenter OS are highly elastic, self-managing and self-healing. With the Virtual Datacenter OS from VMware, businesses large and small can benefit from the flexibility and the efficiency of the “lights-out” datacenter.
My reactions to this are mixed. But I'm sharing them to shed light on what this announcement means for data center operators, MSPs, and IT Operations folks. Full-disclosure: I work at Cassatt, who's been developing software for data center management now for over 5 years. So the concepts VMware is talking about are actually not new to me at all; I've been living them for a while.
A few initial reactions, and cautionary advice:
- First: I'm thrilled that VMware is finally educating the market that "it's not all about consolidation". There's a bigger "there" there!
- Gartner Research (Tom Bittman), has been touting a "Meta-O/S" for the data center for some time. I'm sure that's where VMware got the idea for VDC-OS. But, their vision was more heterogeneous. More on that later...
- While VMware has coined the term "On-Premesis Cloud", it's been in the news for a while. Here at Cassatt we've been talking about "Internal Clouds" for some time. So has our CEO. Even check out our website. I wonder if VMware took notice...
- The concept of "federating" virtualization management systems (and storage and network) is great. And the fact that VMware has roped-in partners like Savvis, Rackspace, Sungard and more means they're serious. The Gotcha, however, is that the concept works *only* if you buy-into VMware-specific technology. What if you have some other technology like Citrix' (Xen), Microsoft's Hyper-V or Parallels' Virtuozzo? Multiple Virtualization technologies under one roof is gonna happen, folks. Plan for it. (wait for my punchline...)
- Keep in mind that this is a VMware roadmap. Not everything is in place yet.
- What about "The Forgotten 40%"? That is, IT OPS will always have systems that are not virtualized (e.g. transaction processors, directory servers, and other high-throughput and/or Scale-Out architectures). Some analysts believe the number could be as much as 40% of infrastructure. How are you going to manage those systems? You'll Still need a second (if not a third and fourth) management system in addition to vCloud.
So, allow me to take this announcement and append a few nuances to shape it into what IT would want it to look like. Apologies for adding bias :)
- Demand "equal rights" for physical/native systems: The concept of a "meta O/S" for the data center has to include support for all systems, as well as coverage for systems which are *not* virtualized.
- Require VM heterogeneity: Data center operations will have to federate systems (i.e. for failover, capacity extensions, etc.) based on arbitrary technologies. Not VMware only. Fortunately, companies other than VMware are doing this.
- Products are available today: you don't have to buy-into a roadmap. Actually, companies like Cassatt are already delivering on multi-vendor, Physical + Virtual, and "federated" styles of failover, disaster recovery and data center migration.
At the core of where the industry is going is utility computing: This doesn't require that you have to use Virtualization at all, or (if you do) that it come from a single vendor. Cassatt's CTO, in fact, was the designer of one of the best O/S's on the market -- so we know what a real "data center operating system" ought to be.
We'll be at VMware, booth 1440, BTW.
It's that time of year again when all good IT professionals migrate to Las Vegas. Cassatt will be in booth #1440, with some interesting new developments to share. (And, enter to Win a Wii)
Here's a teaser for inquisitive minds:
- Can you Swizzle virtual & physical?
Come by the booth for a complementary drink mixer and find out...
- How will you manage "The forgotten 40%" of your infrastructure?
You'll have to come by and ask!
- What's an Internal Cloud?
Nope. Not a smoker's lounge :)

Ever noticed that the two hottest topics in IT today are Data Center Efficiency and Cloud Computing? Ever wondered if the two might be related? I did. And it’s clear that the media, industry analysts – and most of all IT OPs – have missed this relationship entirely. I now feel obligated to point out how and why we need to make this connection as soon as we can.
Let me cut to the chase: The most theoretically-efficient IT compute infrastructure is a Utility Computing architecture – essentially the same architecture which supports PaaS or “cloud computing”. So it helps to understand why this is so, why today's efficiency “point solutions” will never result in maximum compute efficiency, and why the “Green IT” movement needs to embrace Utility Computing architectures as soon as it can.
To illustrate, I’ll remind you of one of my favorite observations: How is Amazon Web Services able to charge $0.10/CPU-Hour, (equating to ~$870/year) when the average IT department or hosting provider has a loaded server cost of somewhere between $2,000-$4,000/year? What does Amazon know that the rest of the industry doesn’t?
First: A bit of background
Data center efficiency is top-of-mind lately. As I’ve mentioned before, a recent EPA report to U.S. Congress outlined that over 1.5% of U.S. electricity is going to power data centers, and that number may well double by 2011. Plus, according to an Uptime Institute White Paper, the 3-year cost of power to operate a server will now outstrip the original purchase cost of that server. Clearly, the issues of high cost and limited capacity for power are currently hamstringing data center growth, and the industry is trying to find a way to overcome it.
Why point-solutions and traditional approaches will miss the mark
I regularly attend a number of industry organizations and forums on IT energy efficiency, and have spoken with all major industry analysts on the topic. And what strikes me as absurdly odd is that the industry (taken as a whole) is missing-the-mark on solving this energy problem. Industry bodies – mostly driven by large equipment vendors – are mainly proposing *incremental* improvements to “old” technology models. Ultimately these provide a few % improvement here, a few % there. Better power supplies. DC power distribution. Air flow blanking panels. Yawn.
These approaches are oddly similar to Detroit trying to figure out how to make its gas-guzzlers more efficient by using higher-pressure tires, better engine control chips and better spark plugs. They’ll never get to an order-of-magnitude efficiency improvement on transportation.
Plus, industry bodies are focusing on metrics (mostly a good idea) that will never get us to the major improvements we need. Rather, the current metrics are lulling us into a misplaced sense of complacency. To wit: The most oft-quoted data center efficiency metrics are the PUE (Power Use Effectiveness), and it’s reciprocal, the DCiE (Data Center Infrastructure Efficiency). These essentially say, “get as much power through your data center and to the compute equipment, with as little siphoned-off to overhead as possible.”
While PUE/DCIE are nice metrics to help drive overhead (power distribution, cooling) power use down, they don’t at all address the efficiency with which the compute equipment is applied. For example, you could have a pathetically low-level of compute utilization, but still achieve an incredibly wonderful PUE and DCIE number. Sort of akin to Detroit talking about transmission efficiency rather than actual mileage.
These metrics will continue to mislead the IT industry unless it fundamentally looks at how IT resources are applied, utilized and operated. (BTW, I am more optimistic about the Deployed HW Utilization Efficiency “DH-UE” metric put forth by the Uptime Institute in an excellent white paper, but rarely mentioned)
Where we have to begin: Focus on operational efficiency rather than equipment efficiency
So, while Detroit was focused on incremental equipment efficiency like higher tire pressure and better spark plugs to increase mileage, Toyota was looking at fundamental questions like how the car was operated. The Prius didn’t just have a more efficient engine, but it had batteries (for high peak needs), regenerative braking (to re-capture idle “cycles”), and a computer/transmission to “broker” these energy sources. This was an entirely new operational model for a vehicle.
The IT industry now needs a similar operationally-efficient re-engineering.
Yes, we still need more efficient cooling systems and power distribution. But we need to re-think how we operate and allocate resources in an entirely new way. This is the ONLY approach that will result in Amazon-level cost reductions and economies-of-scale. And I am referring to cost reductions WITHIN your own IT infrastructure. Not to outsourcing. A per-CPU cost basis under $1,000/year, including power, cooling, and administration. What IT Operations professional doesn’t desire that?
Punchline: The link between efficiency, cloud computing & utility computing architectures
What the industry has termed “utility computing” or Platform-as-a-Service (a form of “cloud” computing) provides just this ideal form of operational-efficiency and energy-efficiency to IT.
Consider the principles of Utility Computing (the architecture behind “clouds”): Only use compute power when you need it. Re-assign it when-and-where it’s required. Retire it when it’s not needed at all. Dynamically consolidate workloads. And be indifferent with respect to the make, model and type of HW and SW. Now consider the possibilities of using this architecture within your four walls.
Using the design centers above, power (and electricity cost) is *inherently* minimized because capital efficiency is continuously maximized. Always, regardless of the variation from hour-to-hour or month-to-month. And, this approach is still compatible with “overhead” improvements such as to cooling and power distribution. But it always guarantees that the working capital of the data center is continuously optimized. (Think: the Prius engine isn’t running all the time!)
On top of this approach, it would then be appropriate to re-focus on PUE/DCIE!
The industry is slowly coming around. In a recent article, my CEO, Bill Coleman, pointed out a similar observation: Bring the “cloud” inside, operate your existing equipment more efficiently, and save power and $ in the process.
I’m only waiting for the rest of the industry to acquiesce the inherent connection between Energy efficiency, operational efficiency, power efficiency, and the architectures behind cloud computing.
Only then will we see a precipitous drop in energy consumed by IT, and the economies-of-scale that technology ought to provide.
I just learned of a brand-new analyst report (and upcoming webinar) regarding a broad survey of desktop and server power management. I expect that it will completely dwarf the very high-level survey of data center power management products I recently made.
The work is being done by The 451 Group, and sister company Tier 1 Research. The webinar, titled "Power Management 2008-2012 Managing and Monitoring IT Energy Use From the Desktop to the Datacenter" is on September 4 from 12:00 to 1:00pm EST. Register Here.
The webinar appears to coincide with a forthcoming 76 page report from The 451 titled "Eco-Efficient IT: Power Management – 2008-2012". Clearly, Cassatt is part of their wide-ranging analysis. Their summary:
"IT power consumption is causing significant financial, operational and ethical problems for many organizations – and excessive consumption may in future be a compliance issue (accurate measurement of power is required by some planned laws and incentive schemes). However, most organizations have no technology in place for measuring, aggregating and tracking power use; indeed, such technology has only recently become available. IT suppliers have belatedly realized the importance of this issue, and the race is on to develop products and establish them in the marketplace.
"This report examines this topic with a focus on managing power, managing datacenters and investing in and understanding the eco-efficient IT agenda.
"The 451 Eco-Efficient IT (ECO-IT) service tracks and analyzes key developments, from the Kyoto Protocol to datacenter effectiveness, from electricity prices to telepresence. Ecoefficiency is becoming a key consideration for technology vendors, end users, service providers and investors. The 451 Group provides insight to help organizations negotiate this new challenge and profit from the opportunity.
I'm digging the report, simply b/c of the TOC - something everyone should consider reading before undertaking *any* form of IT energy efficiency project:
SECTION 4: Datacenter power management
4.1 Datacenter power management – The technology
4.2 Effectiveness and ROI of datacenter power management
4.2.1 Calculating ROI
4.3 Market development and buyer attitudes
4.4 Reasons to be cautious: Market barriers to datacenter power management adoption
4.5 Toward the energy-aware, dynamic datacenter
4.5.1 The power management policy engine
4.6 Visibility into IT assets, dependencies and policies
4.7 Improving visibility into mechanical and electrical equipment
4.8 Virtualization and power management
4.9 Technical issues associated with virtualization
Like virtualization, power management is not an end-in-and-of-itself. Rather, it should be considered as part of a portfolio of initiatives IT & Facilities management need to consider when considering options.
I'm planning a future post to cover my philosophy of what a truly operationally-efficient data center implies; stay tuned.







