During 2023 there was the obvious rise of using AI (and other forms of LLMs) to assist marketing’s efficiency and effectiveness. However, most of the uses of AI I’ve seen were in the areas of (a) content generation, and (b) CS and chatbots.
Entering 2024, I’m hoping that we see deeper use of AI/ML to enhance the marketing domains of understanding customers, enriching marketing datasets, and better analysis of customer journeys.
In short, I believe – and hope to see – the following B2B marketing trends progress… and hope that B2B Marketing leaders begin to invest in the following:
- Use of Mass-Customization in Marketing
- Turn to Data-Driven Customer Targeting
- The Death of Traditional Lead Attribution
I’ve also added a few resources below each observation if you’d like to look more deeply. Please leave comments, notes and other insights so that others can learn from this!
1. Use of Mass-Customization in Marketing:
AI is now being applied to “mass customization” (personalization-at-scale) of content, marketing outreach, web experience, and even product experience. As marketing departments mature from using LLMs/AI for simple content creation, they’ll find that combining AI with customer data enrichment will open the floodgates to creating even better Ideal Customer Profiles (ICP).
AI tools are being increasingly used to enrich customer data; not just to add missing contact information and addresses, but to uncover individual customer use-cases, jobs-to-be-done, existing tech-stacks, previous purchase history, social network engagement and more. This data can be assembled for much more precise targeting, outreach, product recommendations, and of course content.
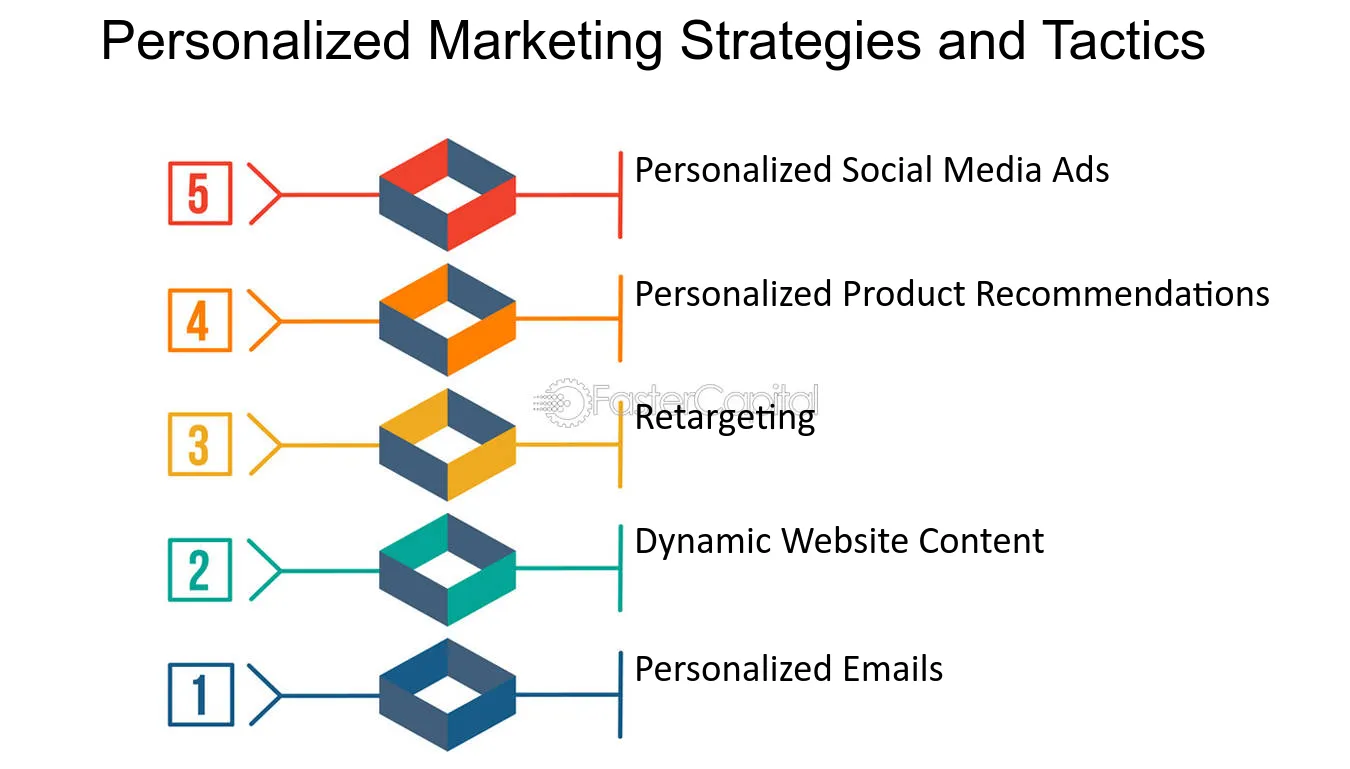
In 2024 I hope to see marketing leaders decrease their “spray-and-pray” outbound marketing and demand generation – in favor of using AI-based tools that will both harvest/enrich contact information (see below) to generate more relevant, ICP-based outreach. The results could be an order-of-magnitude improvement in outreach response and click-through rates.
For deeper insight:
- The Intersection Of AI & ABM: Transforming B2B Content Syndication (Mark Nachlis)
- The Power of Personalization in Mass Customization (Faster Capital)
2. Data-Driven Customer Targeting:
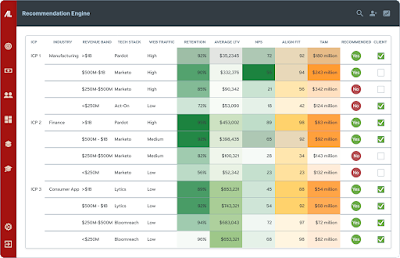
Building Ideal Customer Profiles has largely resided in the area of assembling personas - and doing so has largely been qualitative research, experimentation, and a pinch of guesswork.
In 2024, I see top-of-funnel ICP creation becoming far more precise and data-driven, leveraging new AI-driven data enrichment, correlation, and analysis. This will be guided by targeting the highest lifetime-value customers, as well as those with the lowest acquisition costs.
As the trend continues (I hope) we’ll also see a shift to augmenting existing Customer Relationship (CRM) systems with newer Customer Data Platforms (CDPs). CDPs collect/amass more information about customers than what is simply entered by sales and marketing teams. I see CDPs leveraging publicly-available 3rd-party data sources, social, etc. to add to customer profiles. The results will (a) help better understand existing customers and needs, as well as (b) help predict sources and ways to ID net new customers.
For deeper insight:
- What is an ideal customer profile? (Unusual Ventures)
- The Framework for Ideal Customer Profile Development (Gartner)
- Best Customer Data Platforms (Forbes Advisor)
3. The Death of Lead Attribution
In the very recent past, Lead Attribution and last-touch tracking was used to determine what resources “caused” customers to convert (and what org got the credit). In my opinion, this approach has been simplistic and short-sighted.
In addition, cookie restrictions and web tracking limitations are making these approaches even more difficult to implement.
In response, marketers will begin to use more holistic (and privacy-centric) approaches to finding the sources of marketing and sales leads. Strategies like adopting first-party data collection, data enrichment tools, investing in predictive analytics, leveraging AI-driven models, and emphasizing contextual targeting will gain traction.
Plus, advanced analytics and ML algorithms enables a deeper understanding of customer behavior and allows for more detailed attribution models that take into account various touchpoints and interactions. One of the key benefits of using ML in attribution modeling is its ability to identify the most significant touchpoints in the customer journey, even when those touchpoints may not be obvious.
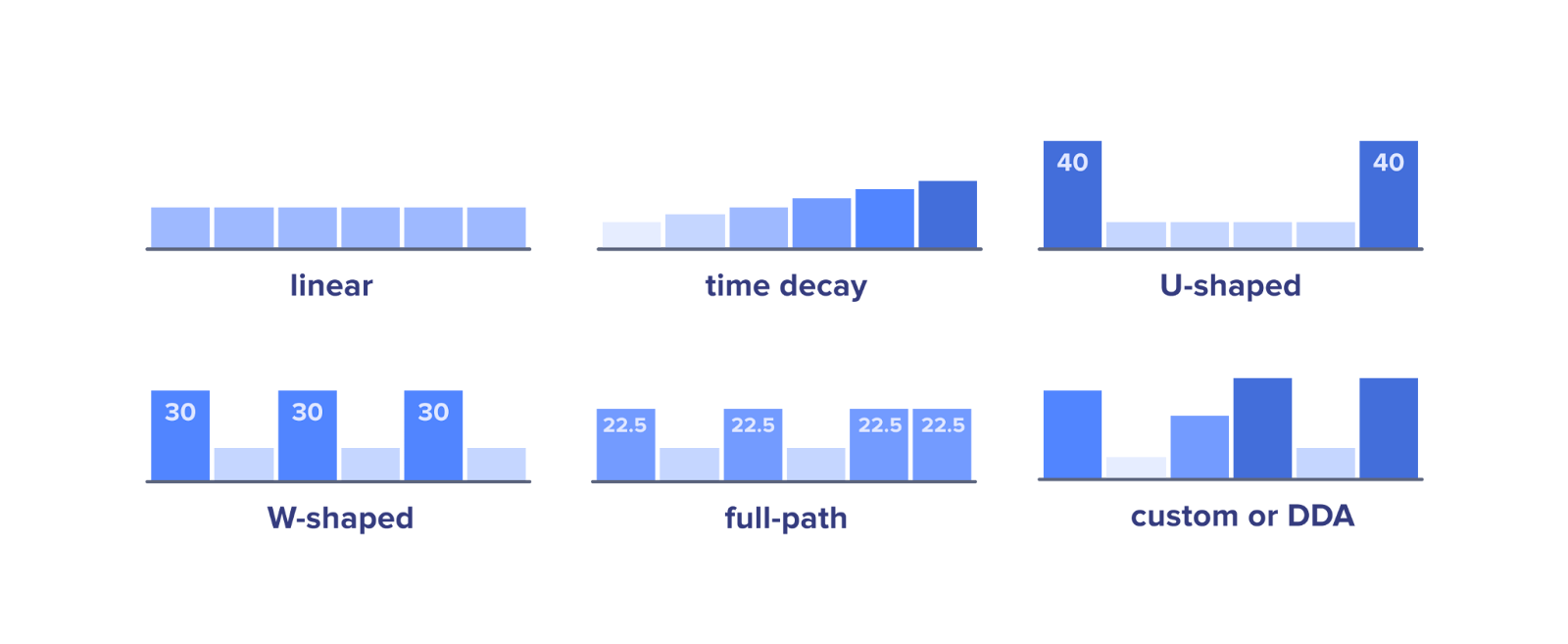
For deeper insight:
- Future of marketing attribution: How AI changes the game (Segmentstream)
- Why It’s Time to Change Your Attribution Model (Pecan)
Final Thought
These themes are simply observations I've made as a practitioner; please leave comments, notes and other insights so that others can learn from this!